The Impact of Mixtral
Can You Feel The MoE?
Since the infamous BitTorrent link launch of Mixtral, Mistral’s Mixture of Expert (MoE) model, there’s been renewed attention1 paid to MoE models.
This week, Mistral released the paper accompanying the model. This feels like a great time to dig into the details of the Mixtral model and the impact that it’s having on the MoE and LLM communities so far.
Mixtral and the MoE paradigm
We discussed the intuition behind MoE models in An Analogy for Understanding Mixture of Expert Models:
In Sparse Mixture of Experts (MoEs), we swap out the
MLP layersof the vanilla transformer for anExpert Layer. The Expert Layer is made up of multiple MLPs called “Experts”. For each input we select one expert to send that input to. In this way, each token has different parameters applied to it. A dynamic routing mechanism decides how to map tokens to Experts.
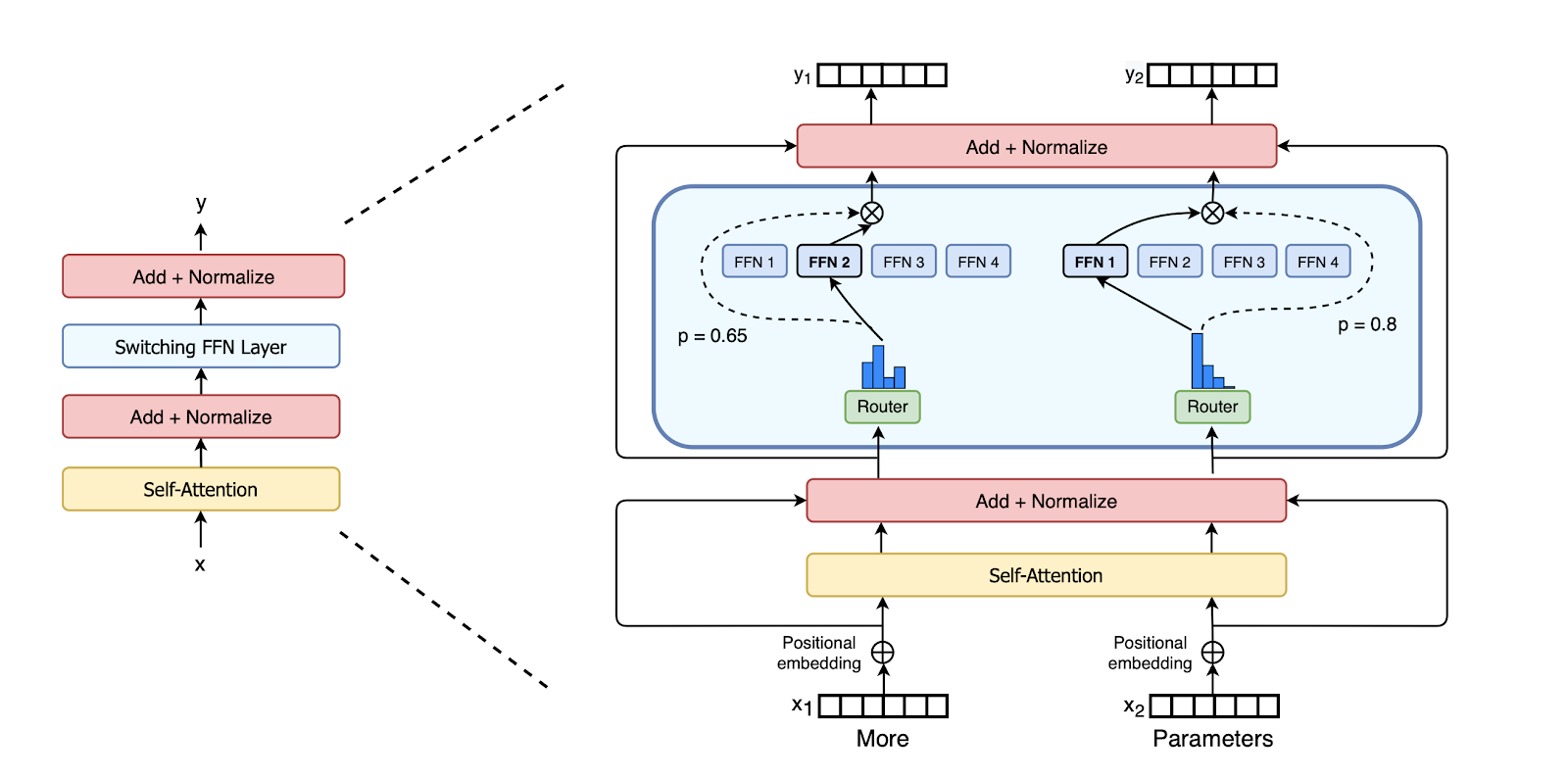
This approach gives models more parameters 2 without requiring more compute or latency for each forward pass. MoE models also typically have better sample efficiency - that is, their performance improves much faster than dense transformers in training, when given the same amount of compute. This isn’t quite a free lunch because it requires more memory to store the model for inference, but, if you have enough memory, it’s pretty great.
Mixtral 8x7B has the backbone of Mistral-7B (their previous model). As with Mistral-7B, Mixtral uses Group Query Attention and Sliding Window Attention. The main changes are a 32k context window out of the box and replacing the Feed Forward Networks (FFNs) with Mixture of Expert (MoE) layers.
Mixtral opts for an MoE layer with 8 FFN experts which are sparsely activated
by choosing the top 2 at each layer. 3
Having 8 experts means that where the original Mistral had a single FFN per
transformer block, Mixtral has 8 separate FFNs. 4
Rather than each token rather than being processed by all the parameters, a
routing network dynamically selects the top 2 experts for each token depending
on the content of the token itself. Hence, though the total parameter count is
47B, the “active” parameter count (i.e. the number of parameters used for each
forward pass) comes in at 13B. 5
Succinctly an MoE layer is given as:
\[\displaystyle \sum_{i=0}^{n-1}G(x)_i \cdot E_i(x),\]where G is a gating function which is 0 everywhere except at 2 indices and where each \(E_i\) is a single expert FFN. Note that in the above formula since most of the entries of the sum are zeros (as G(x) is zero for most i), we only have to compute some of the \(E_is\) rather than all of them. This is where MoEs have computational efficiency advantages over using bigger models or using an ensemble of models.
There is an MoE layer in each of the transformer blocks (32 in this case) and hence we do this routing procedure 32 times for each forward pass. In a traditional ensemble model, N (8 in this case) models have their predictions averaged, so there are 8 token paths. We can compare the number of possible paths that each token could take in an MoE to these ensemble methods:
At each layer we choose 2 of the 8 experts to process our token. There are \(\binom{8}{2}\) = 28 ways to do this. And this happens at each of the 32 layers giving \(28^{32}\) possible paths overall, which is huge6! 🤯 The variety of possible paths here points towards increasingly Adaptive Computation in models. In Adaptive Computation, we consider models which handle different tokens with different parameters and different amounts of compute.
Up until now there have been a two barriers to truly performant and stably trainable MoEs:
Problem 1: Training MoEs properly from a mathematical perspective
MoE models have an inherently discrete step, the hard routing, and this typically harms the gradient flow. Typically we want fully differentiable functions for backprop and MoEs aren’t even continuous! Considering mathematically plausible approximations to the true gradient can hugely improve MoE training. Recent approaches like Sparse Backpropagation and Soft MoE for encoders provide better gradient flow and hence more performant models.
Problem 2: Training MoEs efficiently
Compared to their FLOP-class, MoEs are larger models. Their size means that there are real benefits to effective parallelisation and minimising communication costs. Many frameworks such as DeepSpeed MoE now support MoE training in a fairly hardware efficient way.
Having overcome both of these issues, we’re now ready to use MoEs more in practise.
Notes on Mixtral’s paper
Evals
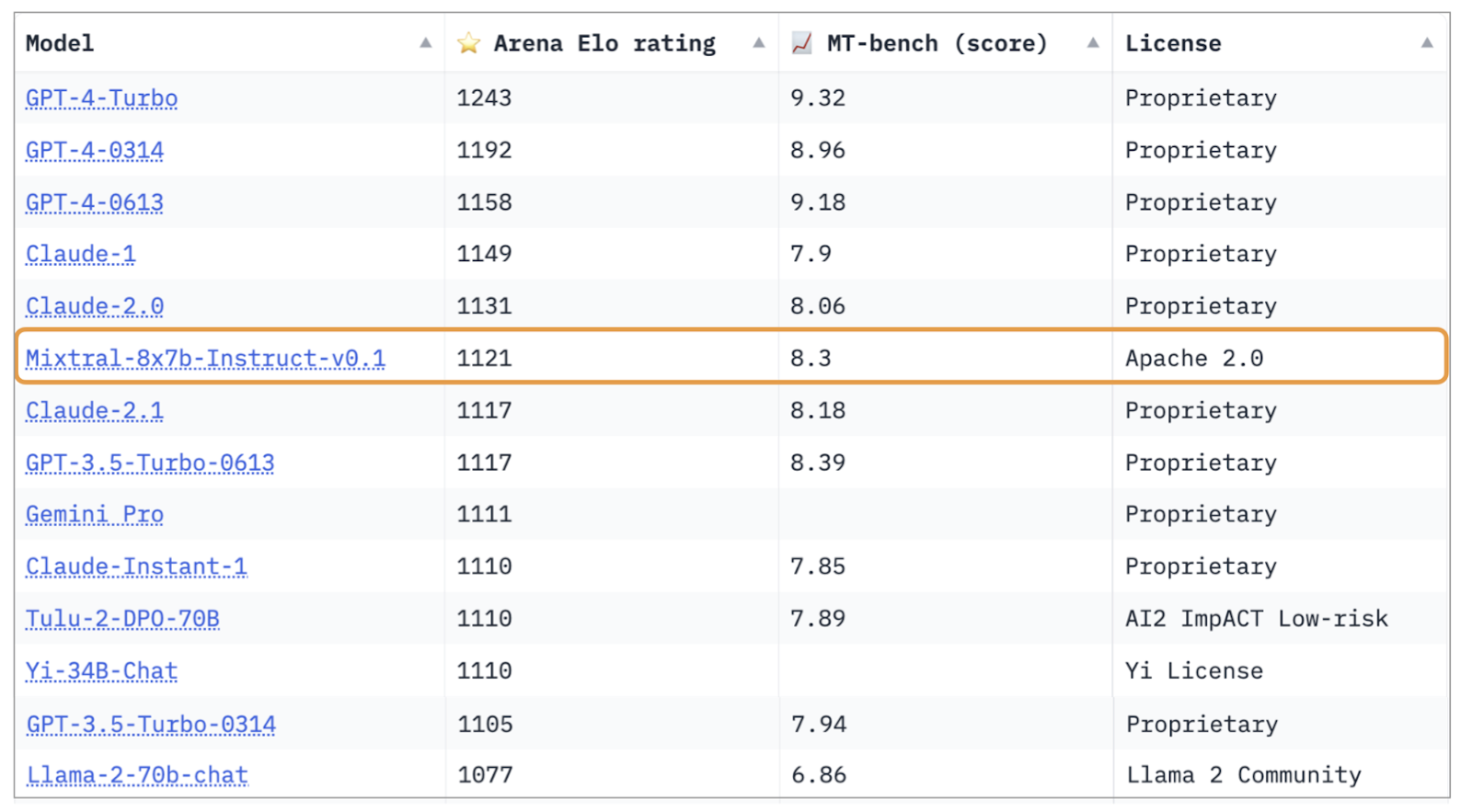
The Mixtral base model outperforms popular (and larger) models like Llama 2 70B, Gemini Pro and GPT-3.5 on most benchmarks. Note that these models are not only larger in total parameter count but are also larger in active parameter count too!
At the time of writing, Mixtral is the best open-source model and the 3rd best Chat model, only beaten by GPT-4 and Claude 2.0 variants.
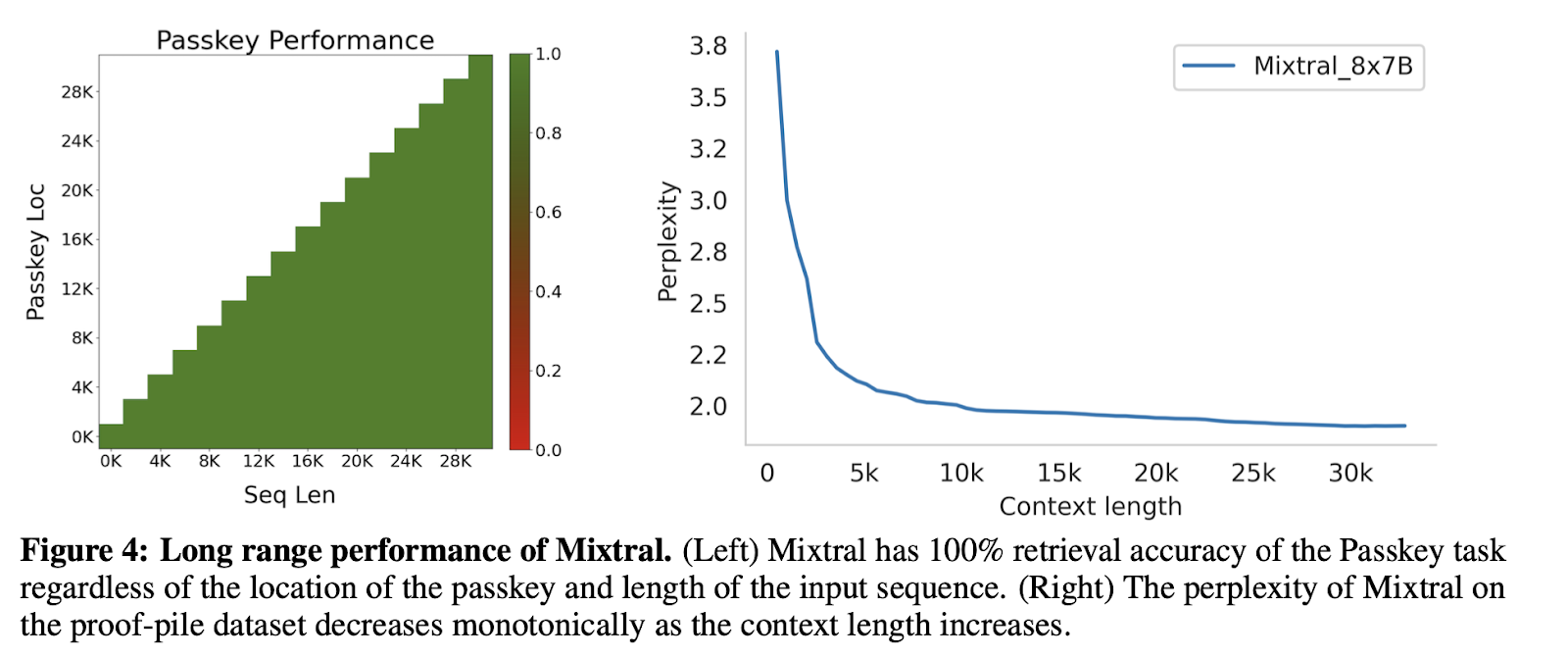
Context Window
Mixtral shows impressive use of its whole 32k context window. The model has relatively good recall even for mid-context tokens.
Instruction Fine-Tuning
Along with the base model, Mistral also released Instruction Fine-Tuned Chat and Assistant models. For alignment, they opted for Direct Preference Optimisation (DPO) which is proving to be a powerful and less finicky alternative to the traditional RLHF. 7
Interpretability
One hypothesis about MoEs is that some experts might specialise in a particular domain (e.g. mathematics, biology, code, poetry etc.). This hypothesis is an old one which has consistently been shown to be mistaken in the literature. Here, the authors confirm, as in previous MoE papers, there is little difference in the distribution of experts used for different domains (although they report being surprised by this finding!). Often experts seem to specialise syntactically (e.g. an expert for punctuation or whitespace), rather than semantically (an expert for neuroscience). 8
Although the distribution of experts is fairly uniform overall, interestingly two adjacent tokens are much more likely to be processed by the same expert, than we might naively predict. In other words, once an expert sees one token, it’s quite likely to also see the next one - experts like to alley-oop themselves! 🏀
This recent paper details ways to exploit this alley-oop property by caching the recently used expert weights in fast memory.
As I’ve noted previously, I’m excited about the explicit modularity in MoE models for increased interpretability.
Notable omissions
There’s little information in the paper about expert balancing techniques. Many different auxiliary losses have been proposed for expert balancing and it would be cool to see which loss function Mistral found to work well at this scale.
The authors are also quite hush about the pretrain, instruction or feedback datasets used to train the model. Given the impressive performance, it’s quite likely that there’s some secret sauce in the dataset compilation and filtering. It seems increasingly likely that data will be a moat for Foundation Model providers 9.
Mixtral in the wild
Impact for On Device LLMs
MoEs win by having increased performance with faster inference. Founder Sharif Shameem writes, “The Mixtral MoE model genuinely feels like an inflection point — a true GPT-3.5 level model that can run at 30 tokens/sec on an M1 MacBook Pro. Imagine all the products now possible when inference is 100% free and your data stays on your device!”
Indeed since the launch of Mixtral, it’s been used in many applications from the enterprise to local chatbots to DIY Home Assistants à la Siri.
As many people use MoE models on-device for the first time, I expect that we will start to see more methods which speed up MoE inference. The Fast MoE Inference paper and MoE specific quantisation like QMoE are all great steps in this direction.
In particular, Quantization can be thought of as storing a model compressed like we do for audio in MP3s. We degrade the quality model slightly and get massive decreases in the memory that it requires. We can typically quantise MoEs even more aggressively than dense models and retain strong performance.
Impact for Foundation Model Companies
Mistral was only started a matter of months ago with a super lean team and is already SOTA for Open Source models. This is impressive from their team but it may also suggest that Foundation Models are being commodified real quick.
Originally Mistral were offering Mixtral behind their API for \$1.96 per million tokens. Considering GPT-4 is $10-30 at the time of writing, this seemed fair for a hosted API. Within days different inference providers undercut Mistral significantly:
Last week @MistralAI launched pricing for the Mixtral MoE: $2.00~ / 1M tokens.
— JJ — oss/acc (@JosephJacks_) December 15, 2023
Hours later @togethercompute took the weights and dropped pricing by 70% to $0.60 / 1M.
Days later @abacusai cut 50% deeper to $0.30 / 1M.
Yesterday @DeepInfra went to $0.27 / 1M.
Who’s next ??? 📉
There was even one provider who was giving away tokens for free. I know a race to the bottom when I see one…
The consumer/developer is truly winning here but it reiterates the point that Foundation Model companies should expect the value of tokens to fall dramatically. Competition is for Losers, as Peter Thiel might say; it’s very possible to compete away all the profits to zero. 10. It increasingly looks like most of the value captured from an LLM business perspective will likely be in the application layer (e.g. Perplexity, Copilot) and the infrastructure layer (e.g. AWS/Azure).
Impact for the Scientific Community
Mixtral is a huge win for the scientific and interpretability communities. We now finally have a model which is comfortably better than GPT3.5 and whose weights are freely available to researchers.
In addition, given Mixtral shares the same backbone as the previous Mistral 7B, it seems plausible some weights were re-used as initialisations for Mixtral. This approach is known in the literature as Sparse Upcycling. If Sparse Upcycling works, this suggests that the compute required to make great MoE models might be much less than previous thought. Researchers can take advantage of existing models like Llama 2 etc. rather than having to pretrain entirely from scratch, which completely changes which projects are feasible for academics and the GPU-poor.
Open Source ML in the Age of Adaptive Computation
“In 2012 we were detecting cats and dogs and in 2022 we were writing human-like poetry, generating beautiful and novel imagery, solving the protein folding problem and writing code. Why is that?”
Arthur Mensch, Mistral co-founder, suggests most of the reason is “the free flow of information. You had academic labs [and] very big industry labs communicating all the time about their results and building on top of others’ results. That’s the way we [significantly improved] the architecture and training techniques. We made everything work as a community”.
We’re not at the end of the ML story just yet. There’s still science to be done and inventions to be discovered so we still need the free flow of information.
In this house we love Open Source models and papers. 🤗
Expect MoEs to become even more important for 2024. The age of Adaptive Computation is here.
-
If I may ↩
-
which is more knowledge in some sense ↩
-
This is a slight reversal of recent work as many papers had followed the Switch Transformer in only choosing the top 1 expert per layer. We expect that choosing 2 experts allows for more expressivity, more stable training and better gradient flow which is traded off against increased parallel computation in each forward pass. ↩
-
Early MoEs like the Switch Transformer were using 100s of experts per layer. This always seemed a little excessive and working on these models, a good heuristic for choosing the expert number hyperparameter is either the number of experts that will fit into your single GPU memory if you’re mostly doing single batch inference or the number of GPUs that you could do expert parallelism on at inference time if you’re running a high bandwidth API. With this in mind 8 experts seems like a nice middle ground right now for users of an open-source product. ↩
-
This is slightly less than 8x7 =56 total parameters as because attention and embedding parameters are not duplicated). ↩
-
In fact this is quite the understatement, all of these paths are weighted according to the router logits so there’s even more nuance than this in the possible paths that tokens can take. ↩
-
It may also be the case that experts indeed do specialise semantically but that their natural semantic specialisation is not very clear to human researchers ↩
-
at least for companies that don’t produce applications built on top of the models. ↩
-
Sam Altman has colourfully referred to this as the marginal cost of intelligence going to zero ↩
If you'd like to cite this article, please use:
@misc{kayonrinde2024mixtral,
author = "Kola Ayonrinde",
title = "The Impact of Mixtral",
year = 2024,
howpublished = "Blog post",
url = "http://www.kolaayonrinde.com/2024/01/14/mixtral.html"
}