From Sparse To Soft Mixtures of Experts
Mixture of Expert (MoE) models have recently emerged as an ML architecture offering efficient scaling and practicality in both training and inference 1.
What Are Sparse MoEs?
In traditional Sparse MoEs, we swap out
the MLP layers of the vanilla transformer for an Expert Layer. The Expert
Layer is made up of multiple MLPs referred to as Experts. For each input one
expert is selected to send that input to. A dynamic routing mechanism decides
how to map tokens to Experts. Importantly, though this is less mentioned, MoEs
are more modular and hence more naturally interpretable than vanilla
transformers.

Introducing Soft MoEs
The Soft MoE paradigm was introduced by Google researchers in the paper From Sparse To Soft Mixtures of Experts. Unlike Sparse MoEs, Soft MoEs don’t send a subset of the input tokens to experts. Instead, each expert receives a linear combination of all the input tokens. The weights for these combinations are determined by the same dynamic routing mechanism as in Sparse MoEs.
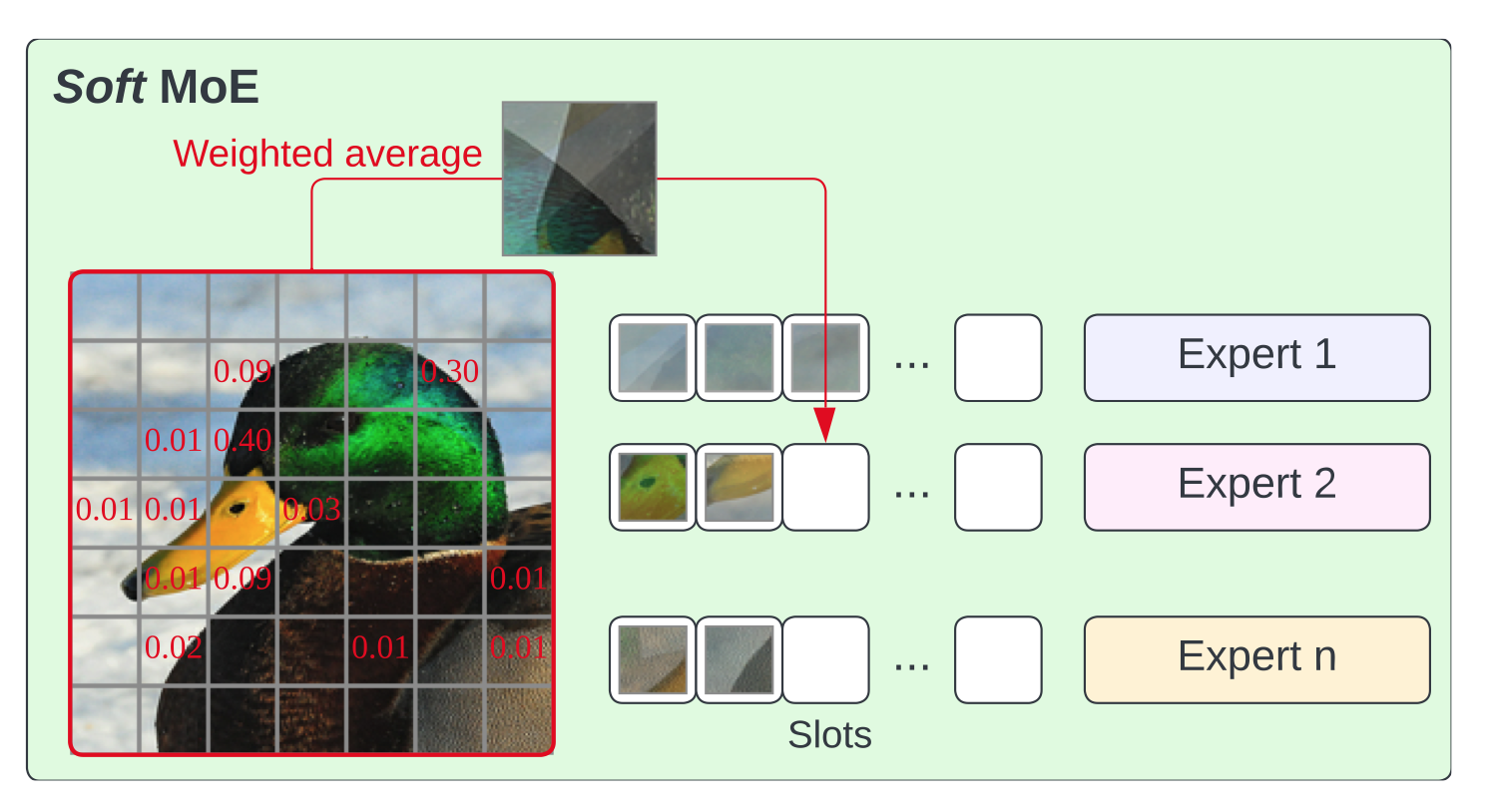
The discrete routing that makes Sparse MoEs so effective also makes them not inherently fully differentiable and can cause training issues. The Soft MoE approach solves these issues, are better suited to GPU hardware and in general outperform Sparse MoEs.
The paper abstract reads:
Sparse mixture of expert architectures (MoEs) scale model capacity without large increases in training or inference costs. Despite their success, MoEs suffer from a number of issues: training instability, token dropping, inability to scale the number of experts, or ineffective finetuning. In this work, we propose Soft MoE, a fully-differentiable sparse Transformer that addresses these challenges, while maintaining the benefits of MoEs. Soft MoE performs an implicit soft assignment by passing different weighted combinations of all input tokens to each expert. As in other MoE works, experts in Soft MoE only process a subset of the (combined) tokens, enabling larger model capacity at lower inference cost. In the context of visual recognition, Soft MoE greatly outperforms standard Transformers (ViTs) and popular MoE variants (Tokens Choice and Experts Choice). For example, Soft MoE-Base/16 requires 10.5× lower inference cost (5.7× lower wall-clock time) than ViT-Huge/14 while matching its performance after similar training. Soft MoE also scales well: Soft MoE Huge/14 with 128 experts in 16 MoE layers has over 40× more parameters than ViT Huge/14, while inference time cost grows by only 2%, and it performs substantially better.
Links to Talk and Slides
I recently gave a talk at EleutherAI, the open-source AI research lab, about Soft MoEs.
You can watch the talk back on YouTube here 2 or view the slides here.
I’m very excited about research ideas working on expanding the SoftMoE paradigm
to autoregressive (GPT-style) models, which is currently an open problem
described in the above talk. Feel free to reach out if you’re interested in or
are currently researching in this area.
-
For more details on MoE models see the Awesome Adaptive Computation repo. ↩
-
Unfortunately the video’s audio quality isn’t as great as it could be, I may look at cleaning this up. ↩
If you'd like to cite this article, please use:
@misc{kayonrinde2023softmoe,
author = "Kola Ayonrinde",
title = "From Sparse To Soft Mixtures of Experts",
year = 2023,
howpublished = "Blog post",
url = "http://www.kolaayonrinde.com/2023/10/20/soft-moe.html"
}